Pacemakerの概要
Pacemakerはオープンソースソフトウェア(OSS)として開発されている、HAクラスタソフトです。以前は「Heartbeat」という名前で開発されていたソフトウェアの後継です。
HAクラスタとは複数のコンピュータをつなげ、全体で1つのコンピュータのように振る舞わせることで、システム全体の稼働率を高める技術です。 HAは「High Availability」(=高可用性)の略で、文字通り、可用性(*)が高い状態を示します。
- 可用性とは、故障等も含めシステムがいかに止まらずに稼働しているかの度合い。
Pacemakerは、複数のコンピュータをNW等で連携し、故障を検知したら他のコンピュータにそれを自動的に肩代わり(フェイルオーバ)させるなどし、「高可用性」を実現します。
Pacemakerの機能と対応可能な故障
Pacemakerは大きく以下5つの機能を有しています。 これにより、サーバで発生しうるほとんどの故障にできます。
-
アプリケーション監視・制御機能
- Apache, nginx, Tomcat, JBoss, PostgreSQL, Oracle, MySQL, ファイルシステム制御、仮想IPアドレス制御、等、多数のリソースエージェント(RA)を同梱しています。また、RAを自作すればどんなアプリケーションでも監視可能です。
-
ネットワーク監視・制御機能
- 定期的に指定された宛先へpingを送信することでネットワーク接続の正常性を監視できます。
-
ノード監視機能
- 定期的に互いにハートビート通信を行いノード監視をします。またSTONITH機能により通信不可となったノードの電源を強制的に停止し、両系稼働状態(スプリットブレイン)を回避できます。
-
自己監視機能
- Pacemaker関連プロセスの停止時は影響度合いに応じ適宜、プロセス再起動、またはフェイルオーバを実施します。また、watchdog機能を併用し、メインプロセス停止時は自動的にOS再起動(およびフェイルオーバ)を実行します。
-
ディスク監視・制御機能
- 指定されたディスクの読み込みを定期的に実施し、ディスクアクセスの正常性を監視します。
以下、共有ディスク構成でPacemakerが対応できる故障箇所のイメージです。(×の個所の故障に対応できます。)
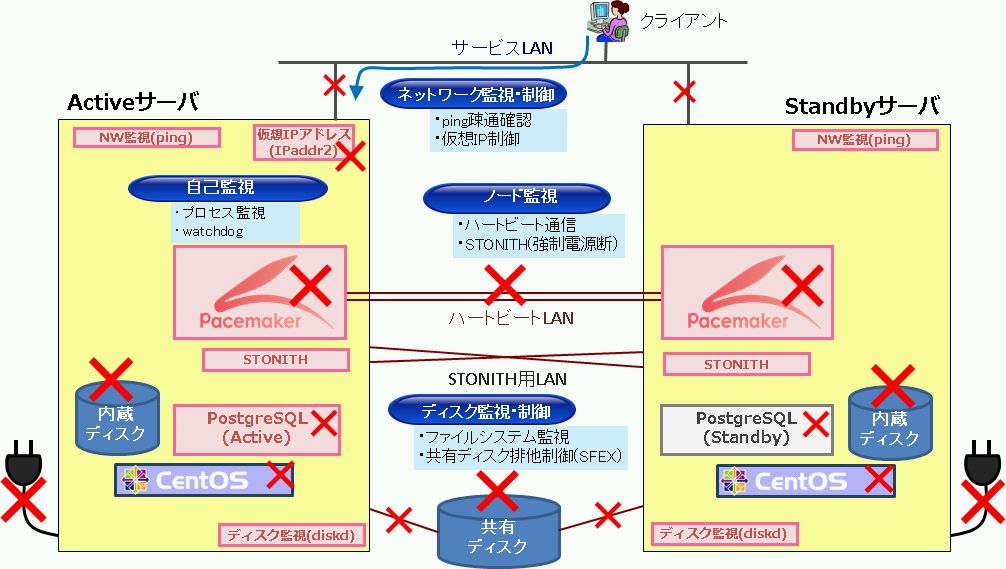
典型的なクラスタ構成
Pacemakerは様々な構成のHAクラスタに対応しています。
大まかに、「データの引継ぎ方法」および「ノード台数」によりクラスタ構成は分類できます。 以下に、Pacemakerが対応可能なクラスタ構成を示します。
データの引継ぎ方法による分類
-
シェアード構成
- 2台のノードの両方からアクセス可能な共有ディスクを用い、データを引き継ぐ構成です。古くから多くのシステムで採用されている最も一般的な構成です。
-
シェアード・ナッシング構成(PG-REX/DRBD利用)
- 共有ディスクは使用せず、ソフトウェアによるデータレプリケーション機能を使用し、データを引き継ぐ構成です。PacemakerではPostgreSQLのストリーミングレプリケーション機能によるPG-REX構成、および、DRBDを用いた構成に対応しています。高価な共有ディスクが不要なため、安価にシステムを構築できます。
ノード台数による分類
-
1+1構成
- 2台のサーバを ActiveサーバおよびStandbyサーバとし、Activeサーバの故障時にはStandbyサーバへフェイルオーバをする構成です。多くのシステムで採用されている最も一般的な構成です。
-
N+1構成
- N台(2台以上)のサーバをActive、1台をStandbyとし、各Activeサーバの故障時には1台のStandbyサーバへフェイルオーバする構成です。Standbyサーバを統合することでサーバの稼働率を上げ無駄を最小限にします。複数台の故障時には1台のStandbyに複数のサービスが稼働する縮退運転となります。(*)
-
N+M構成
- N台のサーバをActive、M台のサーバをStandbyとする構成です。Pacemaker-1.1以降で対応しました。サーバ稼働率と縮退時の性能低下のバランスにより任意の台数で構成できます。
(*)Pacemaker-1.1以降では2つ目以降のフェイルオーバを抑制する設定も可能です。
Pacemakerと稼働率
Pacemakerはフェイルオーバ時に、対象リソースの停止、起動を実行します。 アプリケーションにもよりますが概ね数十秒~数分でフェイルオーバが可能です。
そのためPacemakerは概ね~99.999%の稼働率(1)を実現可能(2)です。 99.9999%では、故障パターンによっては超えてしまう可能性があります。
*1 ある期間でシステムが稼働している時間の割合。可用性の指標となる。 *2 あくまで年に1~2回の故障が発生すると仮定した場合の目安です。リソース構成、アプリケーション、故障発生頻度等により実現できない場合もあります。
以下に稼働率と具体的な稼働時間(年間)、Pacemakerでの対応可否をまとめてみます。
| 稼働率[%] | 許容される年間停止時間 | 実現方法イメージ |
|---|---|---|
| 99 | 約3.6日 | 異常があればメールが送信され、運用者が駆けつけ対応ぐらいでOK |
| 99.9 | 約8.7時間 | 運用者が近くにいればよいが、遠方だと厳しいかも。手動でもいいが、Pacemakerがほしくなるところか。 |
| 99.99 | 約52分 | 商用システムはだいたいこれぐらいを求められるか。Pacemakerで対応可能。 |
| 99.999 | 約5分 | いわゆるファイブナイン。Pacemakerで対応可能。 |
| 99.9999 | 31秒 | リソース構成、故障パターンによってはなんとかPacemakerで対応できる・・・?ハードウェアおよび仮想マシンレベルでのFT(フォールト・トレラント)もほしいところ。 |
Pacemakerバージョンの選び方
Pacemakerは大きく「リソース制御機能」と「クラスタ制御機能」の2つに内部コンポーネントが分かれており、それぞれ選び組み合わせることができます。
それぞれ、メジャーバージョンの違いも含め、以下の選択肢があります。
リソース制御機能
-
Pacemaker 1.0系
-
Pacemaker 1.1系 (最新)
クラスタ制御機能
-
Heartbeat 3系
-
Corosync 1系
-
Corosync 2系 (最新)
一口にPacemakerといっても、上記2×3=6通りの組み合わせが存在するのです。
コンポーネントやバージョンが異なると、当然ながら操作方法や挙動が少しずつ変わります。 中には、安定した動作をしない or そもそもサポートされていない組み合わせもあります。
Linux-HA Japanコミュニティとしては、以下2パターンの組み合わせを推奨しています。
-
推奨組み合わせ1:OS、ミドルバージョン共に最新を使用できる人向け
-
リソース制御機能:Pacemaker 1.1系
-
クラスタ制御機能:Corosync 2系
-
対応OS:RHEL6.XおよびRHEL7.X (含RHELクローンOS)
-
2014年12月 にこの組み合わせのリポジトリパッケージを初めてリリースしました。
-
主にCorosyncの効率的なノード管理により、2の組み合わせより動作が早いです。
-
2の組み合わせでは不可能な構成、動作が新機能により可能です。(N+M構成、リソース配置戦略機能 等)
-
-
-
推奨組み合わせ2:古いOSを使用する、または、すでにPacemaker(+Heartbeat)を使っており、ノウハウ等を流用したい人向け
-
リソース制御機能:Pacemaker 1.0系
-
クラスタ制御機能:Heartbeat 3系
-
対応OS:RHEL5.XおよびRHEL6.X (含RHELクローンOS)
-
2011年のリリース以降、商用システムへの採用も含め、実績が豊富です。
-
ノウハウも多く蓄積されています。
-
現在、新機能の追加は行っていません。
-
リポジトリパッケージの最新は2014年8月リリースの Pacemaker 1.0.13-2.1 です。ダウンロードはこちら
-
-
リソースとリソースエージェント
Pacemakerは、様々なアプリケーションをHAクラスタ化することができます。 Pacemakerでは制御する対象のことをリソースと呼びます。
各リソースの起動/監視/停止といった制御は、リソースエージェント(RA)と呼ばれる各リソース専用モジュールを介して行われます。専用モジュールを介することで、アプリケーション毎の制御方法の違いをラップし、Pacemakerで統一的に扱えるようにしています。
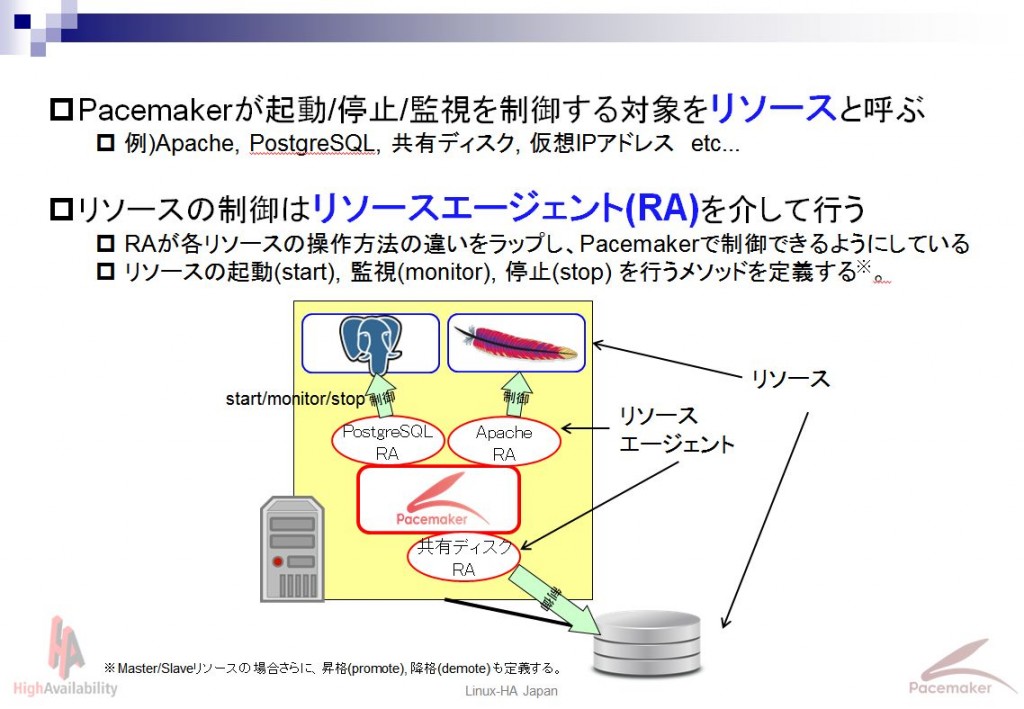
Pacemakerには、Apache, PostgreSQL, Oracle, MySQL, Tomcat, 仮想IPアドレス, ファイルシステムなどなど、多くのリソースエージェントが初めから同梱されています。
また、リソースエージェントは多くはシェルスクリプトで作成されており、Open Cluster Framework(OCF)という仕様に従えば、独自のものを作成し、使用することもできます。 OCFでは、定義すべきメソッド(start/monitor等)、および、返すべき返り値等の規定がされています。メソッドや返り値等の規定に従っていれば、実装するプログラム言語は問いません。ただし、ディストリビューションに依存しないよう、例えばbashではなくshで記述するなどの配慮が必要です。
スプリットブレインと排他制御
HAクラスタでは、リソースをクラスタ内に1つのみに保つことが非常に重要です。 例えば、共有ディスクを有するいわゆるシェアード構成において、複数サーバで同時にマウント/アクセスしてしまうと、共有ディスク上のファイルシステムは破壊されデータが失われてしまいます。また、シェアードナッシング構成においても、例えばDBMSが複数サーバ上で稼働した場合、同一セグメントに複数のDBMSが存在することになり、クライアントからのデータが分散してしまいデータ不整合が発生します。
クラスタを構成するサーバ間の通信が正常な場合は、サーバ同士が連携できるため、リソースを1つのみに保つことは容易です。しかし、サーバ間の通信経路が絶たれたり、あるノードがフリーズするなど、サーバ間で通信できなくなった場合に、上記のような問題が発生します。この状態をスプリットブレインと呼びます。
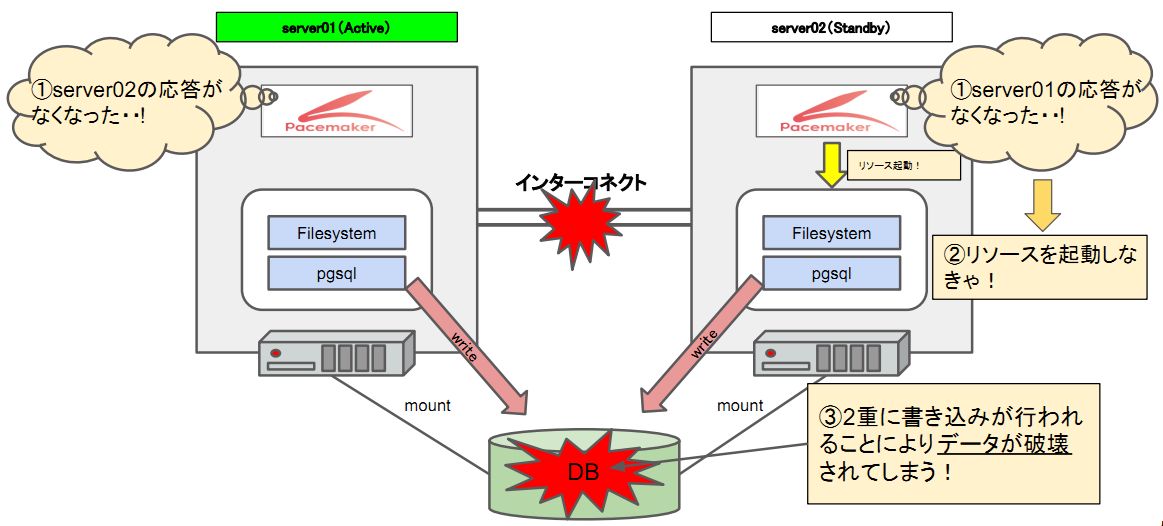 図:排他制御を行わない場合の問題(スプリットブレイン)
図:排他制御を行わない場合の問題(スプリットブレイン)
Pacemakerは、スプリットブレインを防ぐため、以下3種類の排他制御機構を有しています。 この中で、最も信頼性が高く、汎用的なのはSTONITHです。
表:排他制御の種類
| 排他制御の名称(読み) | 概要 | 停止失敗への対応 |
|---|---|---|
| STONITH(ストニス) | ネットワーク越しに相手ノードの電源を強制的に落とす | OK |
| SFEX(エスエフイーエックス) | 共有ディスク上にロック情報を書き込む | NG |
| VIPcheck(ビップチェック) | 仮想IPアドレスへpingを行い相手ノードの状態を確認する | NG |
排他制御機構のうちSTONITHは、リソースの停止が失敗してしまった場合にも有効です。 通常、フェイルオーバ発生時等のリソース停止はリソースエージェントによって行われますが、これが何らかの理由で失敗してしまう場合があります。(ex. プロセスが完全に無応答 等) リソースはクラスタ内に1つのみに保たなければならないので、きちんと停止したことが確認できないとフェイルオーバを継続することはできず、この場合フェイルオーバは失敗してしまいます。 しかし、この場合でも、STONITHを有効にしていれば、停止失敗したノードの電源を強制的に落とすことで、フェイルオーバを継続し、サービスを維持することができます。
排他制御についてさらに詳細は、OSC2015 Tokyo/Fall講演「試して覚えるPacemaker入門 排他制御機能編」をご覧ください。
メーリングリスト
もし、Pacemakerについてわからないことがあれば、遠慮無く日本語MLへ質問してください。