Fedora 19 上でPostgreSQL ストリーミングレプリケーションのクラスタリング
先日リリースされたFedora 19には、Linux-HA Japanで開発したPostgreSQLのストリーミングレプリケーションのクラスタリング機能がついに同梱されました。
Pacemaker のバージョンも開発版で比較的新しい 1.1.9 が同梱されているので、これを使ってPostgreSQLストリーミングレプリケーションのクラスタリングに挑戦してみたいと思います。
環境
今回、Fedoraのインストール手順方法は割愛しますが、以下の環境を用意してください。 ※ 超スモール構成のため、商用での利用は推奨しません。信頼性を確保するには、Pacemaker用やレプリケーション用の専用LANを準備し、STONITHの導入を検討してください。
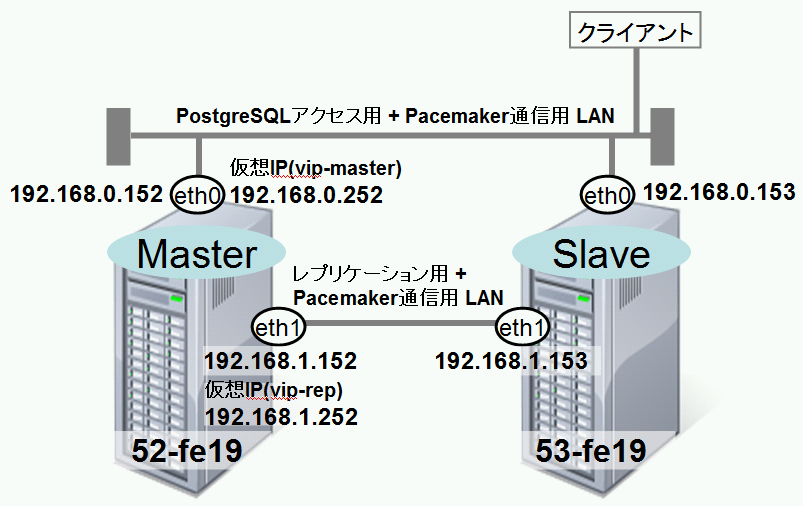
-
ホスト名は、52-fe19 と 53-fe19 とします。 (単に私の手元の環境で使っているホスト名で、深い意味はありません。。。)
-
皆大好きなSELinuxやファイアウォールは無効にしておきます。
-
設定が複雑になるので、ネットワーク監視やディスク監視は行いません。
-
超スモール環境のためネットワークは2本で挑戦します。なお、よく悪者扱いされるNetworkManagerは停止し、IPは手動で設定してください。また、/etc/hostsにホスト名を定義するとトラブル可能性があるので定義しないでください。
-
1本目用途 : PostgreSQLへのアクセス用+Pacemaker通信用
-
52-fe19のIP 192.168.0.152
-
53-fe19のIP 192.168.0.153
-
PostgreSQLアクセス用の仮想IP(vip-master) 192.168.0.252
-
-
2本目用途 : レプリケーション用 + Pacemaker通信用
-
52-fe19のIP 192.168.1.152
-
53-fe19のIP 192.168.1 .153
-
レプリケーション用仮想IP(vip-rep) 192.168.1.252
-
-
インストール
両ノードに、yumを使って必要なパッケージを一気にインストールし、PostgreSQLのアーカイブディレクトリを作成しておきます。(両ノードで実行)
# yum install postgresql-server pacemaker corosync pcs
読み込んだプラグイン:langpacks, refresh-packagekit
(省略)
完了しました!
# su - postgres
$ mkdir /var/lib/pgsql/pg_archive
PostgreSQLの設定
PostgreSQLのデータベースクラスタを作成します。(52-fe19上で実行)
$ cd /var/lib/pgsql/data
$ initdb
データベースシステム内のファイルの所有者は"postgres"ユーザでした。
このユーザがサーバプロセスを所有しなければなりません。
(省略)
成功しました。以下を使用してデータベースサーバを起動することができます。
postmaster -D /var/lib/pgsql/data
または
pg_ctl -D /var/lib/pgsql/data -l logfile start
postgresql.conf ファイルに以下を設定します。その他の設定はデフォルトのままで構いません。なお、synchronous_standby_names パラメータが設定されている場合は、必ずコメントアウトして無効にしておいてください。(52-fe19上で設定)
listen_addresses = '*'
wal_level = hot_standby
synchronous_commit = on
archive_mode = on
archive_command = 'cp %p /var/lib/pgsql/pg_archive/%f'
max_wal_senders=5
wal_keep_segments = 32
hot_standby = on
restart_after_crash = off
replication_timeout = 5000
wal_receiver_status_interval = 2
max_standby_streaming_delay = -1
max_standby_archive_delay = -1
synchronous_commit = on
restart_after_crash = off
hot_standby_feedback = on
pg_hba.conf ファイルを設定します。(セキュリティは全く考慮していません) (52-fe19上で設定)
host all all 127.0.0.1/32 trust
host all all 192.168.0.0/16 trust
host replication all 192.168.0.0/16 trust
PostgreSQLを起動します。(52-fe19上で実行)
$ pg_ctl -D . start
サーバは起動中です。
53-fe19 にデータをコピーします。(53-fe19上で実行)
# su - postgres
$ pg_basebackup -h 192.168.0.152 -U postgres -D /var/lib/pgsql/data -X stream -P
手動でレプリケーション接続できるか試します。53-fe19に/var/lib/pgsql/data/recovery.confを作成します。
standby_mode = 'on'
primary_conninfo = 'host=192.168.1.152 port=5432 user=postgres'
restore_command = 'cp /var/lib/pgsql/pg_archive/%f %p'
recovery_target_timeline = 'latest'
53-fe19のPostgreSQLを起動します。(53-fe19上で実行)
$ pg_ctl -D /var/lib/pgsql/data/ start
52-fe19上で以下のSQLを使ってレプリケーションの状態を確認します。
$ psql -c "select client_addr,sync_state from pg_stat_replication;"
client_addr | sync_state
---------------+------------
192.168.1.153 | async
(1 行)
無事レプリケーション接続できました。では、一旦両ノードのPostgreSQLを停止します。(両ノードで実行)
$ pg_ctl -D /var/lib/pgsql/data stop
$ exit
Corosyncの設定
corosyncの設定ファイル/etc/corosync/corosync.confを用意します。(両ノードで作成)
quorum {
provider: corosync_votequorum
expected_votes: 2
}
aisexec {
user: root
group: root
}
service {
name: pacemaker
ver: 0
use_mgmtd: yes
}
totem {
version: 2
secauth: off
threads: 0
rrp_mode: active
clear_node_high_bit: yes
token: 4000
consensus: 10000
rrp_problem_count_timeout: 3000
interface {
ringnumber: 0
bindnetaddr: 192.168.0.0
mcastaddr: 226.94.1.1
mcastport: 5405
}
interface {
ringnumber: 1
bindnetaddr: 192.168.1.0
mcastaddr: 226.94.1.1
mcastport: 5405
}
}
logging {
fileline: on
to_syslog: yes
syslog_facility: local1
syslog_priority: info
debug: off
timestamp: on
}
Corosyncを起動します。(両ノードで実行)
# systemctl start corosync.service
/var/log/messages に以下のようなメッセージが出ればcorosyncの起動成功です。
[MAIN ] main.c:275 Completed service synchronization, ready to provide service.
ちなみに私の環境では、52-fe19でこのログが出続けていますが、原因はよくわかりません。。。とりあえず動いているようなのでこのまま先に進みます。(おぃ! )
Incrementing problem counter for seqid 2087 iface 192.168.0.152 to [1 of 10]
次はPacemkaerの起動・設定に入っていきます。
Pacemaker起動 + クラスタ設定投入
Pacemaker 1.0.x では、Heartbeat や corosync を移動すると、Pacemakerも自動で起動していましたが、1.1.9は、自動で起動しないため、明示的に起動してあげます。(両ノードで実行)
# systemctl start pacemaker.service
crm_monコマンドでPacemakaerの状態を確認します。
# crm_mon -Afr
Last updated: Mon Jul 8 09:46:27 2013
Last change: Mon Jul 8 09:46:27 2013 via crmd on 52-fe19
Stack: corosync
Current DC: 52-fe19 (402696384) - partition with quorum
Version: 1.1.9-3.fc19-781a388
2 Nodes configured, unknown expected votes
0 Resources configured.
Online: [ 52-fe19 53-fe19 ]
Full list of resources:
Node Attributes:
* Node 52-fe19:
* Node 53-fe19:
Migration summary:
* Node 53-fe19:
* Node 52-fe19:
52-fe19と53-fe19上で無事Pacemakerが起動しました。では、Pacemakerの設定を定義していきます。Fedora 19には慣れ親しんだcrmコマンドが入っていないので、pcsコマンドで設定していきます。以下のコマンドを順番に投入していきましょう。
pcs cluster cib pgsql_cfg
pcs -f pgsql_cfg property set no-quorum-policy="ignore"
pcs -f pgsql_cfg property set stonith-enabled="false"
pcs -f pgsql_cfg resource op defaults resource-stickiness="INFINITY"
pcs -f pgsql_cfg resource op defaults migration-threshold="1"
pcs -f pgsql_cfg resource create vip-master IPaddr2 \
ip="192.168.0.252" \
nic="eth0" \
cidr_netmask="24" \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="block"
pcs -f pgsql_cfg resource create vip-rep IPaddr2 \
ip="192.168.1.252" \
nic="eth1" \
cidr_netmask="24" \
meta migration-threshold="0" \
op start timeout="60s" interval="0s" on-fail="stop" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="ignore"
pcs -f pgsql_cfg resource create pgsql pgsql \
pgctl="/usr/bin/pg_ctl" \
psql="/usr/bin/psql" \
pgdata="/var/lib/pgsql/data/" \
rep_mode="sync" \
node_list="52-fe19 53-fe19" \
restore_command="cp /var/lib/pgsql/pg_archive/%f %p" \
master_ip="192.168.1.252" \
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \
restart_on_promote='true' \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op monitor timeout="60s" interval="9s" on-fail="restart" role="Master" \
op promote timeout="60s" interval="0s" on-fail="restart" \
op demote timeout="60s" interval="0s" on-fail="stop" \
op stop timeout="60s" interval="0s" on-fail="block" \
op notify timeout="60s" interval="0s"
pcs -f pgsql_cfg resource master msPostgresql pgsql \
master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
pcs -f pgsql_cfg resource group add master-group vip-master vip-rep
pcs -f pgsql_cfg constraint colocation add master-group with Master msPostgresql INFINITY
pcs -f pgsql_cfg constraint order promote msPostgresql then start master-group symmetrical=false score=INFINITY
pcs -f pgsql_cfg constraint order demote msPostgresql then stop master-group symmetrical=false score=0
pcs cluster push cib pgsql_cfg
どうしてもcrmコマンドで設定をしたいなら、ここにFedora 18用のcrmshのRPMパッケージがあるので、これを無理やりインストールしてみてください。私の環境では動いてくれました。なお、インストールする には、pssh, python-dateutil, python-lxml パッケージが必要になるので、yum使ってインストールしておきましょう。crmで設定したい場合は以下の設定になります。
property \
no-quorum-policy="ignore" \
stonith-enabled="false"
rsc_defaults \
resource-stickiness="INFINITY" \
migration-threshold="1"
ms msPostgresql pgsql \
meta \
master-max="1" \
master-node-max="1" \
clone-max="2" \
clone-node-max="1" \
notify="true"
group master-group \
vip-master \
vip-rep
primitive vip-master ocf:heartbeat:IPaddr2 \
params \
ip="192.168.0.252" \
nic="eth0" \
cidr_netmask="24" \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="block"
primitive vip-rep ocf:heartbeat:IPaddr2 \
params \
ip="192.168.1.252" \
nic="eth1" \
cidr_netmask="24" \
meta \
migration-threshold="0" \
op start timeout="60s" interval="0s" on-fail="stop" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="ignore"
primitive pgsql ocf:heartbeat:pgsql \
params \
pgctl="/usr/bin/pg_ctl" \
psql="/usr/bin/psql" \
pgdata="/var/lib/pgsql/data/" \
rep_mode="sync" \
node_list="52-fe19 53-fe19" \
restore_command="cp /var/lib/pgsql/pg_archive/%f %p" \
master_ip="192.168.1.252" \
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \
restart_on_promote='true' \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op monitor timeout="60s" interval="9s" on-fail="restart" role="Master" \
op promote timeout="60s" interval="0s" on-fail="restart" \
op demote timeout="60s" interval="0s" on-fail="stop" \
op stop timeout="60s" interval="0s" on-fail="block" \
op notify timeout="60s" interval="0s"
colocation colocation-1 inf: master-group msPostgresql:Master
order order-1 inf: msPostgresql:promote master-group:start symmetrical=false
order order-2 0: msPostgresql:demote master-group:stop symmetrical=false
では、もう一度crm_monコマンドで状態を確認します。
# crm_mon -Afr
Last updated: Mon Jul 8 10:24:21 2013
Last change: Mon Jul 8 10:22:14 2013 via crm_attribute on 52-fe19
Stack: corosync
Current DC: 53-fe19 (419473600) - partition with quorum
Version: 1.1.9-3.fc19-781a388
2 Nodes configured, unknown expected votes
4 Resources configured.
Online: [ 52-fe19 53-fe19 ]
Full list of resources:
Resource Group: master-group
vip-master (ocf::heartbeat:IPaddr2): Started 52-fe19
vip-rep (ocf::heartbeat:IPaddr2): Started 52-fe19
Master/Slave Set: msPostgresql [pgsql]
Masters: [ 52-fe19 ]
Slaves: [ 53-fe19 ]
Node Attributes:
* Node 52-fe19:
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 0000000009000080
+ pgsql-status : PRI
* Node 53-fe19:
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
+ pgsql-xlog-loc : 00000000090000E0
Migration summary:
* Node 52-fe19:
* Node 53-fe19:
う~ん、Masterは正常に起動しましたが、Slaveのpgsql-statusが、HS:syncとHS:aloneを行ったり来たりして安定しません。。。。どうやら、Fedora 19同梱のpgsql RAのバージョンが若干古いようです。/usr/lib/ocf/resource.d/heartbeat/pgsql ファイルを少し修正してみます。901行目の、crm_monを使用している部分を修正します。(両ノードで編集)
(修正前)
crm_mon -n1 | tr -d "\t" | tr -d " " | grep -q "^${RESOURCE_NAME}:.*Master$"
(修正後)
crm_mon -n1 | tr -d "\t" | tr -d " " | grep -q "^${RESOURCE_NAME}[(:].*[):]Master"
ようやく安定しました。 フェイルオーバできるか試してみます。52-fe19上で、PostgreSQLのプロセスをkillしてみます。
# killall -9 postgres
# crm_mon -Afr
Last updated: Mon Jul 8 11:36:23 2013
Last change: Mon Jul 8 11:36:19 2013 via crm_attribute on 53-fe19
Stack: corosync
Current DC: 52-fe19 (402696384) - partition with quorum
Version: 1.1.9-3.fc19-781a388
2 Nodes configured, unknown expected votes
4 Resources configured.
Online: [ 52-fe19 53-fe19 ]
Full list of resources:
Master/Slave Set: msPostgresql [pgsql]
Masters: [ 53-fe19 ]
Stopped: [ 52-fe19 ]
Resource Group: master-group
vip-master (ocf::heartbeat:IPaddr2): Started 53-fe19
vip-rep (ocf::heartbeat:IPaddr2): Started 53-fe19
Node Attributes:
* Node 52-fe19:
+ master-pgsql : -INFINITY
+ pgsql-data-status : DISCONNECT
+ pgsql-status : STOP
* Node 53-fe19:
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 000000000A0000E0
+ pgsql-status : PRI
Migration summary:
* Node 52-fe19:
pgsql: migration-threshold=1000000 fail-count=1000000 last-failure='Mon Jul 8 11:36:13 2013'
* Node 53-fe19:
Failed actions:
pgsql_start_0 (node=52-fe19, call=95, rc=1, status=complete, last-rc-change=Mon Jul 8 11:36:13 2013
, queued=399ms, exec=0ms
): unknown error
無事フェイルオーバしました! 52-fe19 をSlaveとして復旧してみます。フェイルオーバするとデータの整合性が崩れている可能性があるので、52-fe19上のデータを破棄し、53-fe19からデータをコピーし、起動抑止用のロックファイルを削除します。(52-fe19上で実行)
# su - postgres
$ rm -rf /var/lib/pgsql/data/*
$ pg_basebackup -h 192.168.0.153 -U postgres -D /var/lib/pgsql/data -X stream -P
$ rm -f /var/lib/pgsql/tmp/PGSQL.lock
$ exit
# pcs resource cleanup pgsql
# crm_mon -Afr
Last updated: Mon Jul 8 11:44:21 2013
Last change: Mon Jul 8 11:44:20 2013 via crmd on 52-fe19
Stack: corosync
Current DC: 52-fe19 (402696384) - partition with quorum
Version: 1.1.9-3.fc19-781a388
2 Nodes configured, unknown expected votes
4 Resources configured.
Online: [ 52-fe19 53-fe19 ]
Full list of resources:
Master/Slave Set: msPostgresql [pgsql]
Masters: [ 53-fe19 ]
Slaves: [ 52-fe19 ]
Resource Group: master-group
vip-master (ocf::heartbeat:IPaddr2): Started 53-fe19
vip-rep (ocf::heartbeat:IPaddr2): Started 53-fe19
Node Attributes:
* Node 52-fe19:
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
* Node 53-fe19:
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 000000000A0000E0
+ pgsql-status : PRI
Migration summary:
* Node 52-fe19:
* Node 53-fe19:
無事復旧完了しました。
いかがでしたでしょうか? 初めてFedora 19上でPacemakerを動かしてみたので、うまくいくかどうか心配でしたが、(少し変なログが出ているものの)思ったよりも素直に動いてくれました。
本家Pacemakerコミュニティでは、そろそろPacemaker 1.1.10 がリリースされるようで、その数週間後には、安定版の2.0をリリースするという情報も流れています。Linux-HA Japanでも、メジャーバージョンアップに向けて少しづつ動いているようなので、今後の動向が楽しみですね。