OSCデモ機の設定を公開します
こんにちは、Linux-HA Japanのひがしです。
Linux-HA Japanは、オープンソースカンファレンス(OSC)に出展させていただき、講演やデモ機展示などを行っています。(過去の出展報告はこちら)
このデモ機について、展示を見に来ていただいた方から、「参考にしたいので設定を教えてほしい」といったご意見をいただくことがありますので、構成および設定内容について公開します。
以下、2016/03/11 記事作成時点の情報です。
構成概要
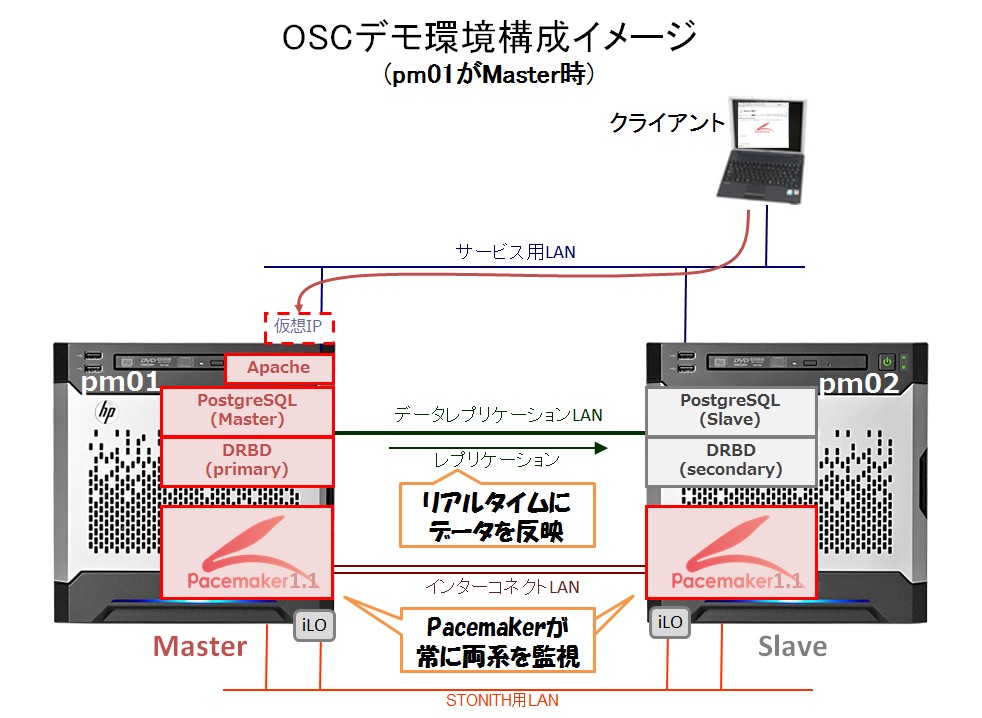
まずは、デモ機の構成全体の概要をご説明します。
デモ機は以下のような構成になっています。
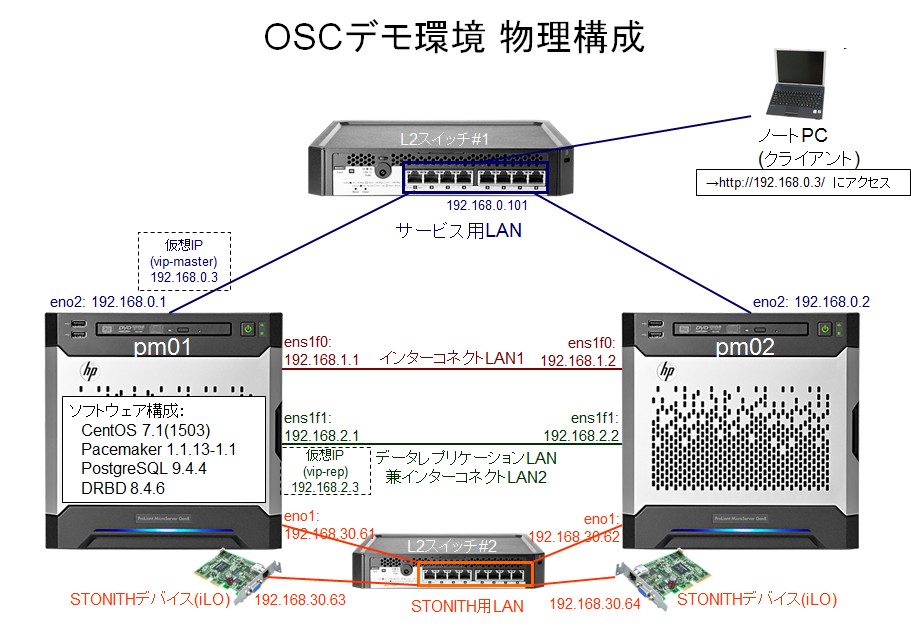
物理的には、以下のような構成です。
この構成のポイントは以下です。
ハードウェア
サーバ本体
HP社のMicroserver Gen8 という機種を使用しています。 この機種は、数万円程度と比較的安価、且つコンパクトですが、iLO(integrated Lights-Out)がオプションとして搭載可能なため、STONITHを有効にしたPacemakerクラスタを組むことができます。
ただし、NICの搭載枚数は、最大4ポートとなります。なので、本デモ構成では、インターコネクトLAN以外のNICが故障した場合、直ちにフェイルオーバが発生します。 商用環境での構成時は、必要に応じ、NICの故障を想定し、bonding等で1ネットワークに複数NICを割り当てることも検討してください。
内蔵ディスクについては、2台搭載し、RAID1でミラーリングしています。PostgreSQLのストリーミングレプリケーション機能およびDRBDを用いて、サーバ間の内蔵ディスクをLAN経由でレプリケーションしているので、共有ディスクは使用していません(コスト低減!)。
L2スイッチ
Microserver Gen8の上部にちょうど設置できる機種です。L2スイッチにはPacemakerとしての要件は特にありません。(もちろん、ハートビート通信のパケットが滞りなく届くことが前提です。ハートビート通信のパケットは大きくないので、GbEが主流の現在、ハートビート通信による輻輳が問題になることはほとんど無いでしょう。)
ただし、デモ構成のため、L2スイッチ自体の故障・冗長化までは考慮しておらず、各ネットワークごとに1台ずつ設置しています。 商用環境での構成時は、スイッチ類の故障も想定し、冗長化等の対策を別途行ってください。
ソフトウェア
OS
CentOS 7.1.1503 です。 Linux-HA Japanで提供のPacemakerリポジトリパッケージはRHELおよびCentOS向けのみとなります。
Pacemaker
Pacemaker 1.1.13-1.1 (el7.x86_64) です。 Linux-HA Japanで提供のPacemakerリポジトリパッケージを使用しています。
なお、PostgreSQLのレプリケーションスロット機能を使用するため、pgsql RAのみコミット2082a7aのものに入れ替えています。この最新のpgsql RAはリポジトリパッケージPacemaker-1.1.14 に同梱される予定です。 レプリケーションスロットについて詳細はこのOSC講演をご覧ください。
DRBD
DRBD 8.4.6 を使用しています。
DRBDについて詳細は株式会社サードウェアのHPが参考になります。
ソースコードがオープンソースとして公開されているのでコンパイルすれば無償で導入できます。
株式会社サードウェア又はDRBD取り扱いパートナーからブロンズ以上のサポートを購入することで、インストールパッケージを入手することもできます。詳細はこちら
PostgreSQL
PostgreSQL本体および関連ツールは、それぞれ以下を使用しています。
postgresql94-9.4.4-1PGDG.rhel7.x86_64 postgresql94-contrib-9.4.4-1PGDG.rhel7.x86_64 postgresql94-server-9.4.4-1PGDG.rhel7.x86_64 postgresql94-libs-9.4.4-1PGDG.rhel7.x86_64
OS同梱のものは若干古いので、公式サイトより、RHEL向けrpmパッケージを入手しました。
ストリーミングレプリケーション機能を用いたいわゆるPG-REX構成となっているので、共有ディスクは存在しません。 DBファイル($PGDATA)は、ローカルの/var/lib/pgsql/dbfp/9.4/pgdata/data に配置しています。
なお、本デモ構成では、PostgreSQLとDRBDを併用していますが、これはあくまでデモのためであり、必ずしも両者を同時に使用しなければならないわけではありません。それぞれ単独で使用することができます。必要に応じ、取捨選択してください。
Apache
OSに同梱の以下バージョンを使用しています。
httpd-2.4.6-31.el7.centos.1.x86_64
ネットワーク
大きく、以下4つのネットワークセグメントがあります。 Pacemakerの仕様としては、ネットワークセグメントは1つでも動作はします。しかし、その1本が少し輻輳しただけでSTONITHが発動する、といったように、可用性が若干落ちてしまうので、ネットワークセグメントは複数に分けることをお勧めします。
-
サービスLAN
-
インターコネクトLAN
-
データレプリケーションLAN
-
STONITH用LAN
サービスLAN
クライアントが接続し、サービス(デモではWebページ)を提供するためのLANです。 クライアントアクセス用の仮想IPアドレス(vip-master)はこのネットワークに付与します。 また、pingリソースによるネットワーク監視はこのネットワークに対し行っています。
インターコネクトLAN
Pacemaker同士が生死確認等をやりとりするためのLANです。 デモ構成では、LANケーブルを直結しています。 また、インターコネクトLANだけは、(NIC枚数が少ないながらも)2系統準備し、簡単にはスプリットブレインが発生しないようにしています。
データレプリケーションLAN
PostgreSQLおよびDRBDがデータレプリケーションを行うためのLANです。 PostgreSQLのデータレプリケーション用の仮想IPアドレス(vip-rep)はこのネットワークに付与します。
STONITH用LAN
STONITH発動時に相手ノードのiLOにipmitoolsコマンドを発行し、強制的に電源を落とすためのLANです。 1サーバにつき、ipmitoolsコマンドを発行するNICと、iLOのポート、の2本のLANケーブルを接続することになります。
CRM設定
PacemakerのCRM設定は以下です。 PG-REX9.4_RHEL7_pm_crmgen_env_OSC_Slot.crm
このCRM設定の特徴をざっくり挙げると以下の通りです。
-
STONITHは有効です。
-
PostgreSQLおよびDRBDはMaster/Slaveリソースとして定義されています。
-
以下のリソースをmaster-groupというGroupリソースとして定義しています。
-
ファイルシステム(/dev/drbd0を/drbd にマウント)
-
Apache
-
vip-master(クライアント接続用仮想IPアドレス)
-
vip-rep(レプリケーション接続用仮想IPアドレス)
-
-
diskdリソースで内蔵ディスクのディスク監視を行っています。
-
pingリソースでサービスLANの監視を行っています。
-
制約を用い、リソース間の起動・停止の条件・順序を制御しています。
-
PostgreSQLのレプリケーションスロット機能が有効です。
このCRM設定で、クラスタを構成した場合の「crm_mon -rfA」の表示は以下のようになります。
Last updated: Wed Mar 2 13:04:40 2016
Last change: Tue Mar 1 13:39:21 2016 by root via crm_attribute on pm01
Stack: corosync
Current DC: pm01 - partition with quorum
Version: 1.1.13-6052cd1
2 Nodes configured
16 Resources configured
Online: [ pm01 pm02 ]
Full list of resources:
Resource Group: master-group
filesystem (ocf::heartbeat:Filesystem): Started pm01
apache (ocf::heartbeat:apache): Started pm01
vip-master (ocf::heartbeat:IPaddr2): Started pm01
vip-rep (ocf::heartbeat:IPaddr2): Started pm01
Resource Group: grpStonith1
prmStonith1-1 (stonith:external/stonith-helper): Started pm02
prmStonith1-2 (stonith:external/ipmi): Started pm02
Resource Group: grpStonith2
prmStonith2-1 (stonith:external/stonith-helper): Started pm01
prmStonith2-2 (stonith:external/ipmi): Started pm01
Master/Slave Set: msPostgresql [pgsql]
Masters: [ pm01 ]
Slaves: [ pm02 ]
Master/Slave Set: msDrbd [drbd]
Masters: [ pm01 ]
Slaves: [ pm02 ]
Clone Set: clnPing [prmPing]
Started: [ pm01 pm02 ]
Clone Set: clnDiskd1 [prmDiskd1]
Started: [ pm01 pm02 ]
Node Attributes:
* Node pm01:
+ default_ping_set : 100
+ diskcheck_status_internal : normal
+ master-drbd : 10000
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 0000001EAC000138
+ pgsql-status : PRI
+ ringnumber_0 : 192.168.1.1 is UP
* Node pm02:
+ default_ping_set : 100
+ diskcheck_status_internal : normal
+ master-drbd : 10000
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
+ ringnumber_0 : 192.168.1.2 is UP
Migration summary:
* Node pm01:
* Node pm02:
以下、設定内容について詳細に解説します。
なお、本構成は基本的にPG-REX構成なので、故障が発生したらどうなるか?といった運用に関することは、OSC2015 Fukuokaでの講演資料 PG-REXで学ぶPacemaker運用の実例 を参考ください。
●STONITHは有効です。
STONITHに関連する設定項目は以下箇所です。それぞれ意味を解説します。
なお、STONITHって何?という方は、このOSC講演:試して覚えるPacemaker入門 排他制御機能編をご覧ください。
3行目:STONITH有効化設定
stonith-enabled="true" \
propertyとしてstonith-enabled=”true” と設定することで、STONITH機能が有効になります。 STONITHを使用しない場合”false”を設定します。
45~51行目:STONITHリソースのグループ化
group grpStonith1 \
prmStonith1-1 \
prmStonith1-2
group grpStonith2 \
prmStonith2-1 \
prmStonith2-2
STONITHリソースとして155~201行目で定義するprmStonithX-Xリソースを管理しやすいようそれぞれグループ化しています。
54~56行目:fencing_topology設定
fencing_topology \
pm01: prmStonith1-1 prmStonith1-2 \
pm02: prmStonith2-1 prmStonith2-2
fencing_topologyは、各ノード(pm01, pm02)をSTONITHするのに、どのリソースを、どの順番で使用するべきかをPacemakerに教えるための設定です。 fencing_topologyは、Pacemaker-1.1系から追加された設定項目です。Pacemaker-1.0系ではこの設定は不要です。
「pm01のSTONITHには、まずprmStonith1-1を使用し、それがダメならprmStonith1-2を使用せよ」と設定しています。(pm02も同様)
ちなみに、prmStonithX-1 は、stonith-helperなので基本的には失敗し、prmStonithX-2が動作し電源断を行うことになります。
155~201行目:STONITHリソース定義
primitive prmStonith1-1 stonith:external/stonith-helper \
params \
pcmk_reboot_retries="1" \
pcmk_reboot_timeout="40s" \
hostlist="pm01" \
dead_check_target="192.168.0.1 192.168.1.1 192.168.2.1 192.168.30.61 192.168.30.63" \
standby_check_command="/usr/sbin/crm_resource -r master-group -W | grep -qi `hostname`" \
standby_wait_time="10" \
run_online_check="yes" \
op start interval="0s" timeout="60s" on-fail="restart" \
op stop interval="0s" timeout="60s" on-fail="ignore"
primitive prmStonith1-2 stonith:external/ipmi \
params \
pcmk_reboot_timeout="60s" \
hostname="pm01" \
ipaddr="192.168.30.63" \
userid="XXXXX" \
passwd="XXXXXXXXXX" \
interface="lanplus" \
op start interval="0s" timeout="60s" on-fail="restart" \
op monitor interval="3600s" timeout="60s" on-fail="restart" \
op stop interval="0s" timeout="60s" on-fail="ignore"
primitive prmStonith2-1 stonith:external/stonith-helper \
params \
pcmk_reboot_retries="1" \
pcmk_reboot_timeout="40s" \
hostlist="pm02" \
dead_check_target="192.168.0.2 192.168.1.2 192.168.2.2 192.168.30.62 192.168.30.64" \
standby_check_command="/usr/sbin/crm_resource -r master-group -W | grep -qi `hostname`" \
standby_wait_time="10" \
run_online_check="yes" \
op start interval="0s" timeout="60s" on-fail="restart" \
op stop interval="0s" timeout="60s" on-fail="ignore"
primitive prmStonith2-2 stonith:external/ipmi \
params \
pcmk_reboot_timeout="60s" \
hostname="pm02" \
ipaddr="192.168.30.64" \
userid="XXXXX" \
passwd="XXXXXXXXXX" \
interface="lanplus" \
op start interval="0s" timeout="60s" on-fail="restart" \
op monitor interval="3600s" timeout="60s" on-fail="restart" \
op stop interval="0s" timeout="60s" on-fail="ignore"
STONITHリソースを定義しています。 各ノードに対し、stonith-helperとipmiの2種類を定義するため、合計で4つのリソースを定義しています。 prmStonith1-Xがpm01ノードをSTONITHするリソース、prmStonith2-Xがpm02ノードをSTONITHするリソースです。
prmStonithX-1 は、stonith-helperという、稼働系と待機系の相撃ちを防止するためのリソースです。 STONITH相撃ちおよびstonith-helperについて詳細はこのOSC講演:試して覚えるPacemaker入門 排他制御機能編をご覧ください。
prmStonithX-2 は、ipmiプラグインという、IPMI仕様に従いサーバの電源断を実行するプラグインを使用しています。 このリソースが、STONITH発動時に実際にサーバの電源断を実施します。 ipmiプラグインはIPMI仕様準拠したハードウェア制御ボードであれば、機種を問わず使用できます。
HP社のサーバに搭載のiLOと呼ばれるハードウェア制御ボードはIPMI仕様に準拠しており、ipmiプラグインを使用することでSTONITH実行が可能となります。詳細は、このページなどを参考にしてください。
ipmiプラグインの設定項目は以下の通りです。
-
hostname:STONITH 対象のノード名を指定します。
-
ipaddr:ハードウェア制御ボード接続用IPアドレスを指定します。
-
userid:ハードウェア制御ボード接続用ユーザ名を指定します。
-
passwd:ハードウェア制御ボード接続用パスワードを指定します。
-
interface:IPMI v1.5の場合は”lan”を、IPMI v2.0の場合は”lanplus”を指定します。
ちなみに、Pacemaker-1.0系のころは、stonith-helperおよびipmiに加え、meatwareと呼ばれるプラグインも併せて設定するのをお勧めしていました。 meatwareは、ipmi等によるSTONITHが何らかの原因で失敗し、保守者による手動電源断が実行された後、Pacemakerに電源断が成功したことを通知するためのプラグインでした。 しかし、Pacemaker-1.1系では、stonith_adminコマンドと呼ばれるコマンドにより、同様のことができるため、meatwareは不要になりました。
210~213行目:STONITHリソースの配置制約
location rsc_location-grpStonith1-3 grpStonith1 \
rule -INFINITY: #uname eq pm01
location rsc_location-grpStonith2-4 grpStonith2 \
rule -INFINITY: #uname eq pm02
STONITHリソースのグループに配置制約を設定しています。 pm01をSTONITHするためのgrpStonith1はpm01(自分自身)では起動しないよう、逆にpm02をSTONITHするgrpStonith2はpm02(自分自身)では起動しないよう、それぞれ設定しています。
Pacemakerは基本的には、自分自身をSTONITHすることはできないため、このような制約をしています。(自分自身をSTONITHすると、STONITHが成功したことをどうやって確認するか?という問題が残るためです。)
各リソースのstopのon-fail=”fence”
以下リソースのstop処理が失敗した場合の挙動(on-fail)は”fence”(=STONITHを実行する)になっています。
-
vip-master
-
filesystem
-
apache
-
pgsql
-
drbd
-
prmPing
-
prmDiskd1
以下、その設定箇所の抜粋です。
primitive vip-master ocf:heartbeat:IPaddr2 \
~中略~
op stop interval="0s" timeout="60s" on-fail="fence"
primitive filesystem ocf:heartbeat:Filesystem \
~中略~
op stop interval="0s" timeout="60s" on-fail="fence"
primitive apache ocf:heartbeat:apache \
~中略~
op stop interval="0s" timeout="60s" on-fail="fence"
primitive pgsql ocf:heartbeat:pgsql \
~中略~
op demote interval="0s" timeout="300s" on-fail="fence" \
~中略~
op stop interval="0s" timeout="300s" on-fail="fence"
primitive drbd ocf:linbit:drbd \
~中略~
op demote interval="0s" timeout="90s" on-fail="fence" \
op stop interval="0s" timeout="100s" on-fail="fence"
primitive prmPing ocf:pacemaker:ping \
~中略~
op stop interval="0s" timeout="60s" on-fail="fence"
primitive prmDiskd1 ocf:pacemaker:diskd \
~中略~
op stop interval="0s" timeout="60s" on-fail="fence"
なお、上記以外のリソースは、仮に停止に失敗し両系で稼動してしまっても問題が無いため、STONITH対象にはしていません。
また、STONITHを有効にしない場合、on-failに”fence”は設定できません。
ちなみに”fence”は”フェンス”で、フェンシングというスポーツのイメージ通り、相手を突き、強制的に停止させるという意味のクラスタ用語からきています。
●PostgreSQLおよびDRBDはMaster/Slaveリソースとして定義されています。
以下の箇所で、PostgreSQLおよびDRBDをMaster/Slaveリソースとして定義しています。 Master/Slaveリソースの概念についてはPacemakerで扱えるリソースの種類をご覧ください。
18~35行目:
ms msPostgresql \
pgsql \
meta \
master-max="1" \
master-node-max="1" \
clone-max="2" \
clone-node-max="1" \
notify="true"
ms msDrbd \
drbd \
meta \
resource-stickiness="1" \
master-max="1" \
master-node-max="1" \
clone-max="2" \
clone-node-max="1" \
notify="true"
Master/Slaveリソースは、 ms Master/Slaveリソース名 primitiveリソース名 [meta 各種パラメータ] という書式で定義します。
metaで設定しているパラメータは、それぞれ以下の意味です。
-
master-max:クラスタ内で稼動可能なMasterリソース数の最大値を設定する。
-
master-node-max:一つのノードで同時に稼動可能なMasterリソース数の最大値を設定する。
-
clone-max:クラスタ内で生成可能なインスタンス数の最大値を設定する。
-
clone-node-max:一つのノードで同時に稼動可能なインスタンスの最大数を設定する。
-
notify:notify処理を行うかどうかを設定する。PostgreSQLおよびDRBDの場合、”true”を指定する。
●以下のリソースをmaster-groupというGroupリソースとして定義しています。
master-groupグループを定義しているのは、以下の箇所です。
11~15行目:
group master-group \
filesystem \
apache \
vip-master \
vip-rep
groupリソースおよびそのメンバとなっている各primitiveリソースの概念、設定については、動かして理解するPacemaker ~CRM設定編~をご覧ください。
また、各リソースエージェントの設定パラメータについては、Pacemakerがインストールされたノードで「crm ra info <リソースエージェント>」コマンドを実行すると詳細に表示されます。 <リソースエージェント>の部分は、例えばapacheの場合「ocf:heartbeat:apache」というようにprimitiveリソースの定義と同様に記載します。
●diskdリソースで内蔵ディスクのディスク監視を行っています。
diskdリソースの定義箇所は以下です。/dev/sda を監視しています。
144~153行目:
primitive prmDiskd1 ocf:pacemaker:diskd \
params \
name="diskcheck_status_internal" \
device="/dev/sda" \
options="-e" \
interval="10" \
dampen="2" \
op start interval="0s" timeout="60s" on-fail="restart" \
op monitor interval="10s" timeout="60s" on-fail="restart" \
op stop interval="0s" timeout="60s" on-fail="fence"
各設定パラメータの意味は以下です。
-
name:監視対象ディスクの状態表示に使用する属性値名を任意の文字列で指定します。crm_monのAttributes欄にこの名前を使用して状態が表示されます。
-
device:監視対象ディスクのデバイス名を指定します。パーティションではなくデバイス自体を設定する必要があります。
-
options:ディスク監視の動作を制御するオプションを指定します。-eはディスク監視機能をスレッドとして動作させます。ディスクアクセスがOS によりブロックされても、正常に監視タイムアウトを発生させることができます。
-
interval:ディスク監視を実施する間隔を秒単位で指定します。
-
dampen:属性値更新時の待ち時間を秒単位で指定します。
●pingリソースでサービスLANの監視を行っています。
pingリソースの定義箇所は以下です。サービスLANを監視するため、サービスLAN側の上位スイッチのIPアドレス(192.168.0.101)に対しpingを発行します。
144~153行目:
primitive prmPing ocf:pacemaker:ping \
params \
name="default_ping_set" \
host_list="192.168.0.101" \
multiplier="100" \
attempts="2" \
timeout="2" \
debug="true" \
op start interval="0s" timeout="60s" on-fail="restart" \
op monitor interval="10s" timeout="60s" on-fail="restart" \
op stop interval="0s" timeout="60s" on-fail="fence"
各設定パラメータの意味は以下です。
-
name:監視対象ネットワークの状態表示に使用する属性値名を任意の文字列で指定します。crm_monのAttributes欄にこの名前を使用して状態が表示されます。
-
host_list:ping 監視先のホスト名またはIPアドレスを指定します。
-
multiplier:ping 監視先への接続が成功した場合に、nameで指定の属性値として保持する値を指定します。
-
attempts:ping 監視先毎のping の試行回数を指定します。
-
timeout:ping 監視先からの応答待ち時間を秒単位で指定します。
-
debug:故障検知時のログ出力の有無を指定します。
●制約を用い、リソース間の起動・停止の条件・順序を制御しています。
以下箇所で、それぞれ、配置制約、同居制約、順序制約を設定しています。 制約について概念および設定は、動かして理解するPacemaker ~CRM設定編~をご覧ください。
204~213行目:配置制約
location rsc_location-msPostgresql-1 msPostgresql \
rule -INFINITY: not_defined default_ping_set or default_ping_set lt 100 \
rule -INFINITY: not_defined diskcheck_status_internal or diskcheck_status_internal eq ERROR
location rsc_location-msDrbd-2 msDrbd \
rule -INFINITY: not_defined default_ping_set or default_ping_set lt 100 \
rule -INFINITY: not_defined diskcheck_status_internal or diskcheck_status_internal eq ERROR
location rsc_location-grpStonith1-3 grpStonith1 \
rule -INFINITY: #uname eq pm01
location rsc_location-grpStonith2-4 grpStonith2 \
rule -INFINITY: #uname eq pm02
前半の6行では、PostgreSQLおよびDRBDが、ネットワークまたはディスクに異常を検知したノードでは停止・フェイルオーバするよう、以下を設定しています。
-
PostgreSQLのMaster/Slaveリソース(msPostgresql)に以下制約を付与します。
-
default_ping_set属性値が未定義または100以下(=pingリソースで故障検知)なら起動しない
-
diskcheck_status_internal属性値が未定義または”ERROR”(=diskdリソースで故障検知)なら起動しない
-
-
DRBDのMaster/Slaveリソース(msDrbd)に以下制約を付与します。
-
default_ping_set属性値が未定義または100以下(=pingリソースで故障検知)なら起動しない
-
diskcheck_status_internal属性値が未定義または”ERROR”(=diskdリソースで故障検知)なら起動しない
-
後半の4行では、自分自身をSTONITHするためのSTONITHリソース(グループ)を自分自身で起動しないよう、以下2点を設定しています。
-
grpStonith1 はノード名がpm01である場合起動しない
-
grpStonith2 はノード名がpm02である場合起動しない
216~222行目:同居制約
colocation rsc_colocation-msPostgresql-clnPing-1 INFINITY: msPostgresql clnPing
colocation rsc_colocation-msPostgresql-clnDiskd1-2 INFINITY: msPostgresql clnDiskd1
colocation rsc_colocation-msDrbd-clnPing-3 INFINITY: msDrbd clnPing
colocation rsc_colocation-msDrbd-clnDiskd1-4 INFINITY: msDrbd clnDiskd1
colocation rsc_colocation-master-group-msPostgresql-5 INFINITY: master-group msPostgresql:Master
colocation rsc_colocation-master-group-msDrbd-6 INFINITY: master-group msDrbd:Master
colocation rsc_colocation-msDrbd-msPostgresql-7 INFINITY: msDrbd:Master msPostgresql:Master
前半の4行では、初期起動時にネットワークおよびディスクの正常性が確認できているノードでのみPostgreSQLおよびDRBDリソースを起動するため、以下を設定しています。
-
msPostgresql と clnPing は必ず同一ノードで起動する。(=clnPingが起動するノードでしかmsPostgresqlは起動しない)
-
msPostgresql と clnDiskd1 は必ず同一ノードで起動する。(=clnDiskd1が起動するノードでしかmsPostgresqlは起動しない)
-
msDrbd と clnPing は必ず同一ノードで起動する。(=clnPingが起動するノードでしかmsDrbdは起動しない)
-
msDrbd と clnDiskd1 は必ず同一ノードで起動する。(=clnDiskd1が起動するノードでしかmsDrbdは起動しない)
後半の3行では、master-groupおよびmsPostgresqlのMaster、msDrbdのMasterが同一ノードで起動するよう、以下を設定しています。
-
master-group と msPostgresqlのMaster は必ず同一ノードで起動する。(=msPostgresqlのMasterが起動するノードでしかmaster-groupは起動しない)
-
master-group と msDrbdのMaster は必ず同一ノードで起動する。(=msDrbdのMasterが起動するノードでしかmaster-groupは起動しない)
-
msDrbdのMaster と msPostgresqlのMaster は必ず同一ノードで起動する。(=msPostgresqlのMasterが起動するノードでしかmsDrbdのMasterは起動しない)
225~232行目:順序制約
order rsc_order-clnPing-msPostgresql-1 0: clnPing msPostgresql symmetrical=false
order rsc_order-clnDiskd1-msPostgresql-2 0: clnDiskd1 msPostgresql symmetrical=false
order rsc_order-clnPing-msDrbd-3 0: clnPing msDrbd symmetrical=false
order rsc_order-clnDiskd1-msDrbd-4 0: clnDiskd1 msDrbd symmetrical=false
order rsc_order-msDrbd-master-group-5 INFINITY: msDrbd:promote master-group:start symmetrical=false
order rsc_order-msPostgresql-master-group-6 INFINITY: msPostgresql:promote master-group:start symmetrical=false
order rsc_order-msPostgresql-master-group-7 0: msPostgresql:demote master-group:stop symmetrical=false
order rsc_order-master-group-msDrbd-8 0: master-group:stop msDrbd:demote symmetrical=false
前半4行では、初期起動時にネットワークおよびディスクの正常性が確認できているノードでのみリソースを起動するため、以下4点を設定しています。 同居制約の前半4行と合わせて設定することで、初期起動時のネットワークおよびディスクの正常性確認の効果を発揮します。
-
clnPing→msPostgresqlの順で起動する。ただし、停止順は特に定義しない(並列停止可能)。
-
clnDiskd1→msPostgresqlの順で起動する。ただし、停止順は特に定義しない(並列停止可能)。
-
clnPing→msDrbdの順で起動する。ただし、停止順は特に定義しない(並列停止可能)。
-
clnDiskd1→msDrbdの順で起動する。ただし、停止順は特に定義しない(並列停止可能)。
次の2行では、PostgreSQLおよびDRBDのMaster化(promote)と、master-groupの起動順序を設定しています。 PostgreSQLおよびDRBDのMaster化が完了し、サービス提供準備が整ってから、仮想IPアドレス等を付与するよう制御しています。
-
必ず、msDrbdをMaster化(promote)してから、master-groupを起動する。
-
必ず、msPostgresqlをMaster化(promote)してから、master-groupを起動する。
最後の2行では、PostgreSQLおよびDRBDと、master-groupの停止順序を設定しています。 PostgreSQLのdemote(≒停止)の前に、PostgreSQLがリッスンしている仮想IPアドレスが停止してしまうと、PostgreSQLのログにエラーが出力されるため、それを回避するために設定しています。
-
msPostgresqlをSlave化(demote)してから、master-groupを停止する。
-
msDrbdをSlave化(demote)してから、master-groupを停止する。
●PostgreSQLのレプリケーションスロット機能が有効です。
以下の箇所でPostgreSQLのprimitiveリソースを定義しています。
96~120行目:
primitive pgsql ocf:heartbeat:pgsql \
params \
pgctl="/usr/pgsql-9.4/bin/pg_ctl" \
start_opt="-p 5432" \
psql="/usr/pgsql-9.4/bin/psql" \
pgdata="/var/lib/pgsql/dbfp/9.4/pgdata/data" \
pgdba="postgres" \
pgport="5432" \
pgdb="template1" \
rep_mode="sync" \
node_list="pm01 pm02" \
master_ip="192.168.2.3" \
restore_command="/bin/cp /var/lib/pgsql/dbfp/9.4/pgarch/arc1/%f %p" \
repuser="repuser" \
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \
stop_escalate="0" \
xlog_check_count="0" \
replication_slot_name="osc_demo_slot" \
op start interval="0s" timeout="300s" on-fail="restart" \
op monitor interval="10s" timeout="60s" on-fail="restart" \
op monitor role="Master" interval="9s" timeout="60s" on-fail="restart" \
op promote interval="0s" timeout="300s" on-fail="restart" \
op demote interval="0s" timeout="300s" on-fail="fence" \
op notify interval="0s" timeout="60s" \
op stop interval="0s" timeout="300s" on-fail="fence"
基本的にはPG-REXの手順に従っていますが、最新機能であるレプリケーションスロット機能を有効にするため”replication_slot_name”というパラメータが設定されています。
レプリケーションスロット機能が盛り込まれたpgsql RAは、Pacemakerリポジトリパッケージの1.1.14に同梱予定です。 (本デモ構成ではpgsql RAのみコミット2082a7aのものに入れ替えています。)